精惠自動化(東莞) 專業提供多樣化工業自動化解決方案

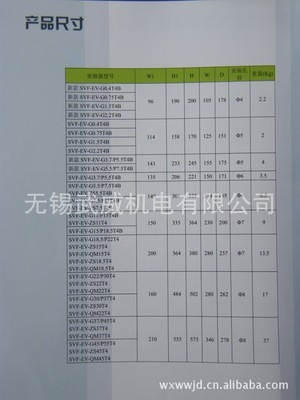
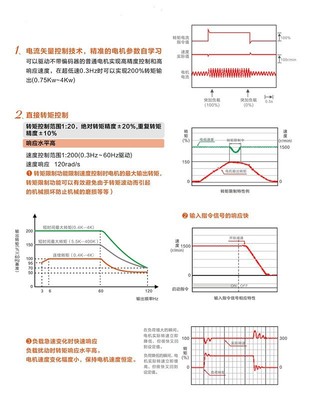
精惠自動化(東莞)有限公司是一家專注于工業自動化領域的專業企業,致力于為各類制造行業提供高效、可靠的自動化產品和解決方案。公司主營一系列優質自動化設備,包括端子機專用變頻器、智能計數器、齒輪減速馬達、電腦橫機專用變頻器等核心產品。這些設備廣泛應用于電子制造、紡織機械、包裝設備等領域,幫助客戶提升生產效率、降低能耗。
公司產品線還包括智能溫控器、色標傳感器(電眼)、智能定時器、直流控制器、智能電壓電流表以及電磁電機調速器,以滿足不同工業場景的需求。精惠自動化還代理知名品牌如亞泰變頻器和臺安變頻器,確保產品質量和性能的穩定性。
如需了解更多信息或咨詢產品詳情,歡迎撥打公司電話:0769-82052205。精惠自動化以專業的技術支持和周到的售后服務,成為眾多企業信賴的合作伙伴,助力客戶實現智能化轉型。
如若轉載,請注明出處:http://m.kengken.cn/product/1.html
更新時間:2026-06-18 06:54:51